The Backbone of Modern AI: Understanding Supervised Learning
The Backbone of Modern AI: Understanding Supervised Learning
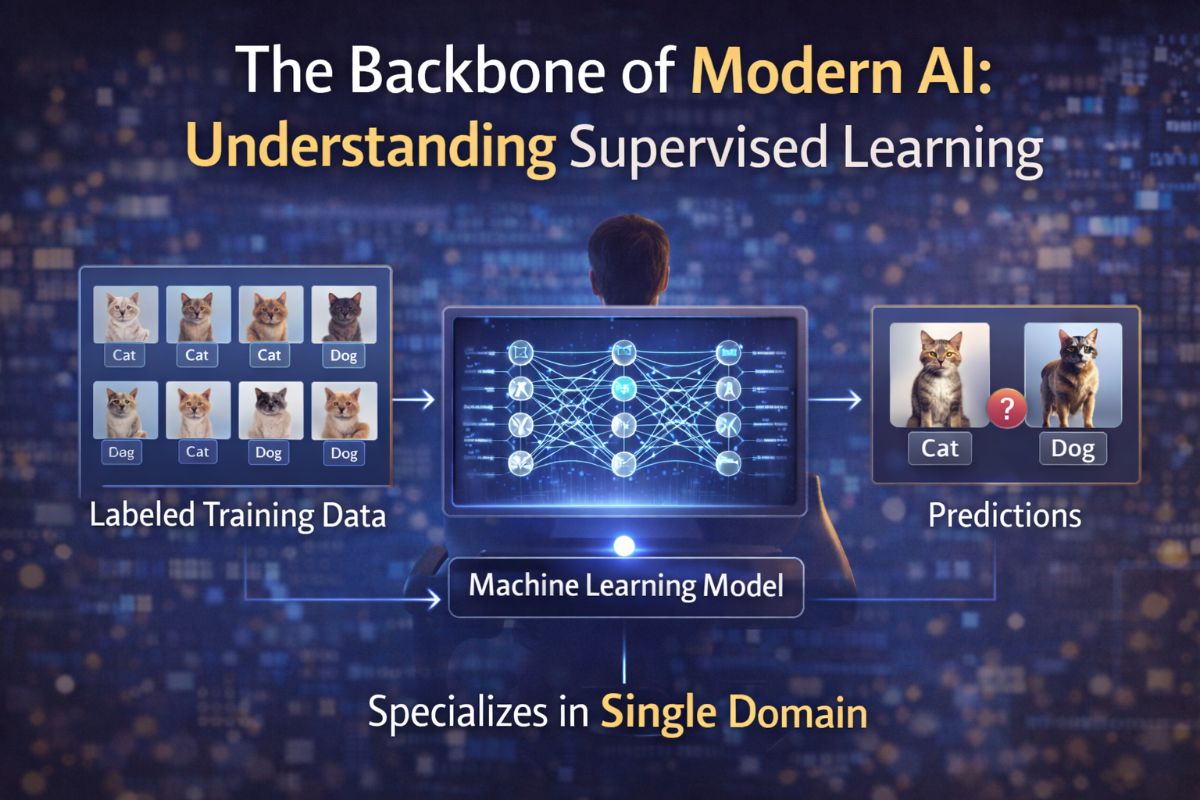
In the rapidly evolving landscape of artificial intelligence, one question remains fundamental for both developers and business leaders: Which type of machine learning is trained on labelled data? The answer is Supervised Learning. While contemporary buzzwords like "Generative AI" and "Self-Supervised Learning" dominate headlines, supervised learning remains the workhorse of the industry, providing the precision and reliability required for mission-critical applications.
At its core, supervised learning functions much like a student-teacher relationship. The algorithm (the student) is provided with a training dataset (the textbook) that contains both the raw input and the correct output, known as labels. By analyzing these pairs, the model learns the underlying mapping function to predict labels for new, unseen data. Industry giants like IBM Watson have leveraged this approach for decades to provide high-stakes enterprise solutions in finance and healthcare.
The Mechanics of Labeled Data: Classification vs. Regression
Supervised learning is generally categorized into two primary tasks, depending on the nature of the output:
- Classification: This involves predicting a discrete category or class. Common examples include identifying whether an email is spam, or determining if a medical image shows signs of disease. Tools like Google Lens use sophisticated classification models to recognize objects in real-time by comparing them against millions of labeled images.
- Regression: This task predicts continuous numerical values. It is widely used in weather forecasting, stock market prediction, and real estate valuation. Platforms such as H2O.ai excel at these predictive analytics, allowing enterprises to automate complex regression modeling at scale.
Real-World Impact and Market Trends
The demand for high-quality labeled data has birthed a massive sub-industry. According to recent market analysis, the global data collection and labeling market is projected to reach over $17 billion by 2030, growing at a CAGR of 25%. This growth is driven by the realization that "Data-Centric AI"—a movement spearheaded by visionaries like Andrew Ng—is often more effective than simply building more complex models.
In the creative and productivity space, supervised learning acts as the "finishing school" for large models. While a model like Google Gemini or OpenAI is pre-trained on massive amounts of unlabeled data, it is Supervised Fine-Tuning (SFT) that teaches it how to follow instructions, maintain a specific tone, or provide accurate coding assistance.
Supervised Learning in the Era of Generative AI
It is a misconception that Generative AI has moved past labeled data. In fact, many of the most popular tools today rely on it for safety and alignment. For example:
- Content Creation: Tools like Jasper and Copy.ai utilize models that have been supervised to understand marketing frameworks and brand voices.
- Visual Synthesis: High-end video generation platforms such as Synthesia and HeyGen use supervised techniques to map facial movements and lip-syncing precisely to audio inputs.
- Language Refinement: Grammarly uses supervised classification to identify grammatical errors and suggest tone adjustments based on billions of labeled corrections.
The "Why" Behind the Labels: Challenges and Future Directions
The primary challenge of supervised learning is the cost and bottleneck of human labeling. Creating a high-quality labeled dataset is labor-intensive and expensive. This is why we see a shift toward Reinforcement Learning from Human Feedback (RLHF), a hybrid approach used by Claude (Anthropic) to align AI behavior with human values through a combination of labels and preference ranking.
As we look forward, the industry is moving toward Semi-Supervised Learning and Synthetic Data Generation. By using a small amount of human-labeled data to train a model that can then label millions of other points, companies can scale faster. However, the foundational "ground truth" provided by supervised learning will remain the gold standard for accuracy and safety in the AI world for the foreseeable future.
Conclusion
Supervised learning is more than just a category of machine learning; it is the bridge between raw data and actionable intelligence. Whether it's power-user tools for data science or creative platforms for content generation, the precision afforded by labeled data ensures that AI remains a reliable partner in human progress. For those looking to integrate these technologies, exploring the diverse tools on AI Tool Hub is the first step toward mastering the data-driven future.